Díky programům, jako je Canva, už není problém si nechat vygenerovat video. A modely pro generování videa se vyvíjejí neuvěřitelným tempem. Ale mnoho současných systémů dokáže generovat pouze tichý výstup – video bez zvuku. Umělá inteligence Deepmind společnosti Google k němu doplňuje další důležitou ingredienci –bohatou zvukovou kulisu pro dění na obrazovce, například dramatickou hudbu a realistické zvukové efekty.
Zdroj: X, DeepMindWe're sharing progress on our video-to-audio (V2A) generative technology. 🎥
— Google DeepMind (@GoogleDeepMind) June 17, 2024
It can add sound to silent clips that match the acoustics of the scene, accompany on-screen action, and more.
Here are 4 examples - turn your sound on. 🧵🔊 https://t.co/VHpJ2cBr24 pic.twitter.com/S5m159Ye62
Google Deepmind to komentuje: "Jedním z dalších velkých kroků při oživování generovaných filmů je vytvoření zvukové stopy pro tato němá videa." A současné možnosti umělé inteligence v technologii převodu videa na zvuk (Video to Audio, V2A) také demonstruje na několika videích. Do V2A generátoru je potřeba zadat video a textový pokyn v přirozeném jazyce. Umělá inteligence na základě toho doprovodí obrázky odpovídajícími zvuky, jako je hudba, zvukové efekty nebo dialogy.
Zdroj:
YouTube, Deepmind
Umělá inteligence dokáže také generovat zvukovou stopu pro řadu tradičních záběrů, včetně archivních materiálů, němých filmů a dalších - otevírá to podle Googlu širší škálu tvůrčích možností. V2A technologie může generovat neomezený počet zvukových stop pro libovolné vstupní video. Volitelně lze také definovat "pozitivní výzvu", která nasměruje generovaný výstup k požadovaným zvukům, nebo naopak "negativní výzvu", která jej odvede od nežádoucích zvuků.
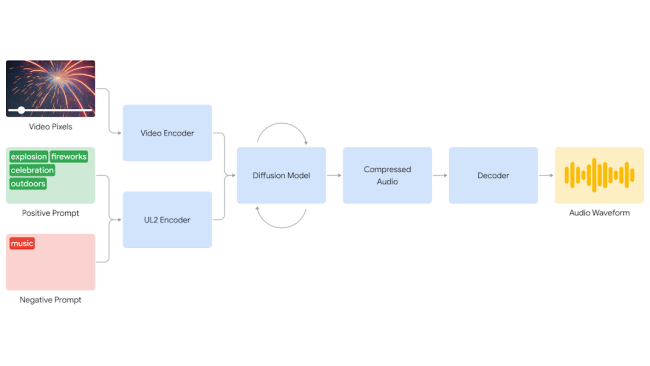
Zdroj: Google DeepMind
Podle Googlu se umělá inteligence učí "spojovat určité zvukové události s různými vizuálními scénami a reagovat na informace uvedené v anotacích nebo přepisech". V oblasti synchronizace rtů u videí s řečí je třeba ještě zapracovat. V současné době probíhá sběr zpětné vazby od tvůrců a filmařů. Google zdůrazňuje, že se "zavázala k odpovědnému vývoji a používání technologií umělé inteligence". Videa vytvořená pomocí Google Deepmind budou prozatím opatřena vodoznakem. Než bude technologie zpřístupněna široké veřejnosti, projde "přísnými bezpečnostními kontrolami a testy".
Zdroj: DeepMind
Mohlo by vás zajímat